torch7で小さくディープラーニング(3)学習済みデータを使う [人工知能(ディープラーニング)]
前回のプログラムでは、学習済みデータをセーブしました。
今度はそれを使ったプログラムです。
ファイル名は便宜的にT3handan.luaとします。
====T3handan.lua========ここから
require 'nn'
-- 引数をaとbに代入、引数がない場合は0と1にする
a=arg[1] or 0
b=arg[2] or 1
model=torch.load('TEST.t7')
x=torch.Tensor(2)
x[1]=a
x[2]=b
as=model:forward(x)
print("INPUT :",x[1],",",x[2])
print("ANSWER:",as[1])
print("------")
=================ここまで
torchの引数として、ファイル名と引数を二つ与えて実行させます。
th T3handan.lua 2 1
という感じです。
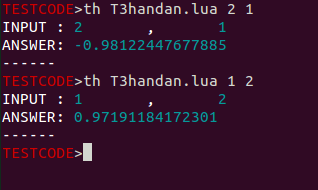
するとこんな感じで結果が返ってきます。
学習済みデータを利用するのはとても簡単です。
早稲田大学のカラー化人工知能は、実はこのプログラムのように、学習済み人工知能モデルで処理をしています。
便利です。
すごく便利です。
でも、なんか物足りない気がする人もいるでしょう。
やはり、人工知能モデルの学習も醍醐味の一つですし。
(人工知能について話を聞けた人の中には「人工知能モデルの学習ノウハウを持っている事は大きなアドバンテージなので、学習済みデータは公開しても、学習ノウハウの公開は考えていない」という方も居たくらいです)
そこまでいかなくとも、人工知能モデルの構築はどんなパズルよりもエキサイティングだと思います…難しいけど面白いです。
そんな訳でこれからは、人工知能モデルの構築と、そこに潜む落とし穴について見ていきましょう!
いゃぁ、人工知能は魔物です…
時には柔順に振る舞いますが、ある時は牙を剥いて飛び掛かってきます…
怖いけど、魅力もあります。

今度はそれを使ったプログラムです。
ファイル名は便宜的にT3handan.luaとします。
====T3handan.lua========ここから
require 'nn'
-- 引数をaとbに代入、引数がない場合は0と1にする
a=arg[1] or 0
b=arg[2] or 1
model=torch.load('TEST.t7')
x=torch.Tensor(2)
x[1]=a
x[2]=b
as=model:forward(x)
print("INPUT :",x[1],",",x[2])
print("ANSWER:",as[1])
print("------")
=================ここまで
torchの引数として、ファイル名と引数を二つ与えて実行させます。
th T3handan.lua 2 1
という感じです。
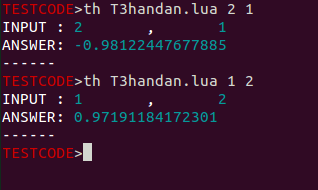
するとこんな感じで結果が返ってきます。
学習済みデータを利用するのはとても簡単です。
早稲田大学のカラー化人工知能は、実はこのプログラムのように、学習済み人工知能モデルで処理をしています。
便利です。
すごく便利です。
でも、なんか物足りない気がする人もいるでしょう。
やはり、人工知能モデルの学習も醍醐味の一つですし。
(人工知能について話を聞けた人の中には「人工知能モデルの学習ノウハウを持っている事は大きなアドバンテージなので、学習済みデータは公開しても、学習ノウハウの公開は考えていない」という方も居たくらいです)
そこまでいかなくとも、人工知能モデルの構築はどんなパズルよりもエキサイティングだと思います…難しいけど面白いです。
そんな訳でこれからは、人工知能モデルの構築と、そこに潜む落とし穴について見ていきましょう!
いゃぁ、人工知能は魔物です…
時には柔順に振る舞いますが、ある時は牙を剥いて飛び掛かってきます…
怖いけど、魅力もあります。
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
- 作者: 斎藤 康毅
- 出版社/メーカー: オライリージャパン
- 発売日: 2016/09/24
- メディア: 単行本(ソフトカバー)




コメント 0