Pytorch1.6をJETSON NANOにインストールする [人工知能(ディープラーニング)]
人工知能フレームワークの変化は本当に激しくて、説明したインストール方法があっという間に使えなくなったりします。
今回、JETSON NANOにPYTORCH1.6をインストールしようとしたところ、いくつかハマりましたので、またインストール方法を説明します。
日本語のサイトでも説明はあるといえばあるのですが、なんかこう、モヤっとすることもあるので基本は公式サイトのインストール方法がいちばんです。
ただし、nVIDIAの公式サイト情報も間違っていることもあるので、気をつけましょう…
では、まずインストールの手順は
https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-6-0-now-available/72048
ここで説明されている手順に従います。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーー
JetPack 4.4 production release (L4T R32.4.3)
Python 3.6 - torch-1.6.0-cp36-cp36m-linux_aarch64.whl
The JetPack 4.4 production release (L4T R32.4.3) only supports PyTorch 1.6.0 or newer, due to updates in cuDNN.
This wheel of the PyTorch 1.6.0 final release replaces the previous wheel of PyTorch 1.6.0-rc2.
ーーーーーーーーーーーーーーーーーーーーーーーーーーーー
(1)インストール用ファイルをダウンロードします。
ここのtorch-1.6.0-cp36-cp36m-linux_aarch64.whlをクリックして、インストール用ファイルをダウンロードします。
(2)次にページの下の方にあるpython3.6用のインストール手順に従います。
ですが、wget .......を実行すると、必要のないpytorch1.4をダウンロードしてしまうので、ここは無視します。
しかも肝心のインストール手順ではやはりpytorch1.4のインストール手順なので、ここの手順も変更します。
実際の手順は以下のようになります。
※必要な依存環境のインストール1
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
※必要な依存環境のインストール2
pip3 install Cython
■このままではPYTORCH1.4をインストールしてしまう手順を変更します→pip3 install numpy torch-1.4.0-cp36-cp36m-linux_aarch64.whl
※わかりやすいように2つの手順に分けます。
※必要な依存環境のインストール3
pip3 install numpy
※pytorch1.6のインストール
pip3 install torch-1.6.0-cp36-cp36m-linux_aarch64.whl
これでpytoch1.6のインストールは完了です。
で、さらにTORCHVISIONのインストールもします。
ここにハマるポイントがあります。
※依存環境のインストール
sudo apt-get install libjpeg-dev zlib1g-dev
公式サイトには
→ git clone --branch <version> https://github.com/pytorch/vision torchvision
とありますが、pytorch1.6にはバージョン0.7.0のtorchvisionが必要なので、実際には以下のような書き方になります。
git clone --branch v0.7.0 https://github.com/pytorch/vision torchvision
■注意■
ここで--branch v0.7.0をつけないでgitするとインストール時にエラーが発生します。
■ディレクトリを移動
cd torchvision
※バージョンの指定
export BUILD_VERSION=0.7.0
※torchvision 0.7.0をインストール
sudo python setup.py install
これでpytorch1.6のインストールが完了です。
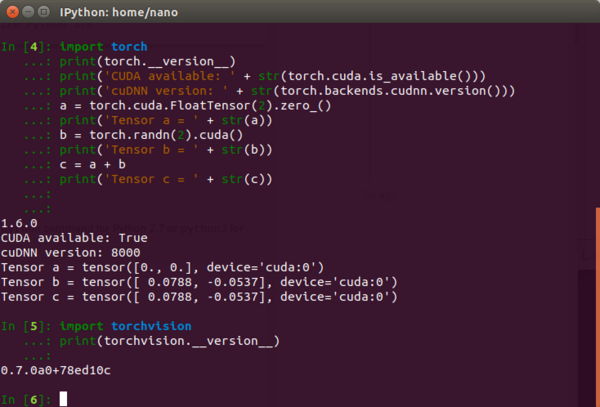
以下のサンプルを実行してエラーがでなければ問題ありません。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
####### torch1.6 sample ########
import torch
print(torch.__version__)
print('CUDA available: ' + str(torch.cuda.is_available()))
print('cuDNN version: ' + str(torch.backends.cudnn.version()))
a = torch.cuda.FloatTensor(2).zero_()
print('Tensor a = ' + str(a))
b = torch.randn(2).cuda()
print('Tensor b = ' + str(b))
c = a + b
print('Tensor c = ' + str(c))
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
####### torchvision 0.7.0 sample ########
import torchvision
print(torchvision.__version__)
今回、JETSON NANOにPYTORCH1.6をインストールしようとしたところ、いくつかハマりましたので、またインストール方法を説明します。
日本語のサイトでも説明はあるといえばあるのですが、なんかこう、モヤっとすることもあるので基本は公式サイトのインストール方法がいちばんです。
ただし、nVIDIAの公式サイト情報も間違っていることもあるので、気をつけましょう…
では、まずインストールの手順は
https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-6-0-now-available/72048
ここで説明されている手順に従います。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーー
JetPack 4.4 production release (L4T R32.4.3)
Python 3.6 - torch-1.6.0-cp36-cp36m-linux_aarch64.whl
The JetPack 4.4 production release (L4T R32.4.3) only supports PyTorch 1.6.0 or newer, due to updates in cuDNN.
This wheel of the PyTorch 1.6.0 final release replaces the previous wheel of PyTorch 1.6.0-rc2.
ーーーーーーーーーーーーーーーーーーーーーーーーーーーー
(1)インストール用ファイルをダウンロードします。
ここのtorch-1.6.0-cp36-cp36m-linux_aarch64.whlをクリックして、インストール用ファイルをダウンロードします。
(2)次にページの下の方にあるpython3.6用のインストール手順に従います。
ですが、wget .......を実行すると、必要のないpytorch1.4をダウンロードしてしまうので、ここは無視します。
しかも肝心のインストール手順ではやはりpytorch1.4のインストール手順なので、ここの手順も変更します。
実際の手順は以下のようになります。
※必要な依存環境のインストール1
sudo apt-get install python3-pip libopenblas-base libopenmpi-dev
※必要な依存環境のインストール2
pip3 install Cython
■このままではPYTORCH1.4をインストールしてしまう手順を変更します→pip3 install numpy torch-1.4.0-cp36-cp36m-linux_aarch64.whl
※わかりやすいように2つの手順に分けます。
※必要な依存環境のインストール3
pip3 install numpy
※pytorch1.6のインストール
pip3 install torch-1.6.0-cp36-cp36m-linux_aarch64.whl
これでpytoch1.6のインストールは完了です。
で、さらにTORCHVISIONのインストールもします。
ここにハマるポイントがあります。
※依存環境のインストール
sudo apt-get install libjpeg-dev zlib1g-dev
公式サイトには
→ git clone --branch <version> https://github.com/pytorch/vision torchvision
とありますが、pytorch1.6にはバージョン0.7.0のtorchvisionが必要なので、実際には以下のような書き方になります。
git clone --branch v0.7.0 https://github.com/pytorch/vision torchvision
■注意■
ここで--branch v0.7.0をつけないでgitするとインストール時にエラーが発生します。
■ディレクトリを移動
cd torchvision
※バージョンの指定
export BUILD_VERSION=0.7.0
※torchvision 0.7.0をインストール
sudo python setup.py install
これでpytorch1.6のインストールが完了です。
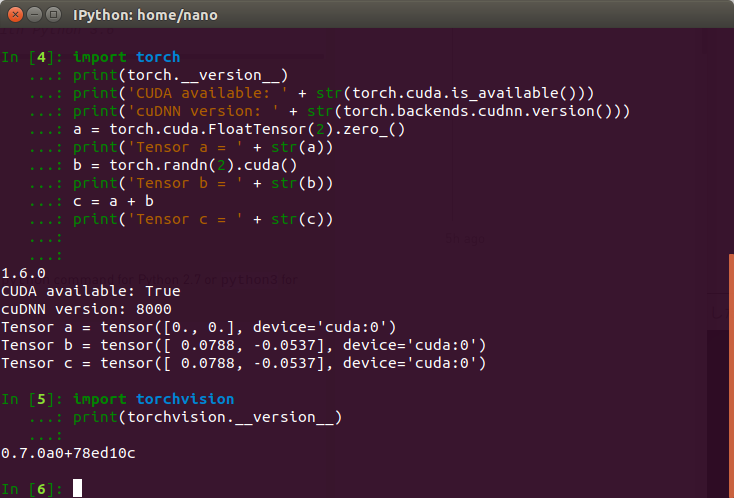
以下のサンプルを実行してエラーがでなければ問題ありません。
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
####### torch1.6 sample ########
import torch
print(torch.__version__)
print('CUDA available: ' + str(torch.cuda.is_available()))
print('cuDNN version: ' + str(torch.backends.cudnn.version()))
a = torch.cuda.FloatTensor(2).zero_()
print('Tensor a = ' + str(a))
b = torch.randn(2).cuda()
print('Tensor b = ' + str(b))
c = a + b
print('Tensor c = ' + str(c))
■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
####### torchvision 0.7.0 sample ########
import torchvision
print(torchvision.__version__)
pinebook proにmecabをインストールする [人工知能(ディープラーニング)]
Pinebook ProというマニアックなLINUXパソコン(MANJAROインストール版)も持っているのですが、そもそもCPUにARMを搭載したlinuxパソコンなのでいろいろなところでつまづきます。
インテル系じゃないんです。情報がありません。
ちなみにスーパーコンピュータ「富嶽」はARMでも特殊なものなので、一緒にはできません。
スマホとかで使われている低電力消費CPUです。
で、最近では、Mecabという形態素解析のライブラリをインストールしようとした時に躓きました。
Mecabのサイトで配布されているプログラムの一部が古くて、
configure cannot guess build type
という警告が出て止まるのです。
なので、これをarm系CPUでインストールする場合には、一部のファイルを手動で新しいものに更新してあげないとインストールできません(makeが動きません)。
#mecabのフォルダに移動
cd mecab-0.996
#古いファイルを削除
rm config.guess
#ネットを通じて新しいファイルをダウンロード
wget https://raw.githubusercontent.com/gcc-mirror/gcc/master/config.guess
これでmakeできるようになります。
あとはインストールの手順通りに
./configure
make
make check
sudo make install
でインストールできます。
※このほか辞書のインストールも忘れないでください。
tar zxfv mecab-ipadic-2.7.0-XXXX.tar.gz
cd mecab-ipadic-2.7.0-*****(実際にあるフォルダ名にしてください)
./configure --with-charset=utf8
make
sudo make install
※辞書の文字コードはデフォルトがeucなので、utf-8に変更しています。
この部分です。
./configure --with-charset=utf8
もし、makeで文字コードの指定を変えたいときは、make cleanとしてから
./configure --with-charset=utf8
もしくは
./configure --with-charset=sjis
と設定しなおして、makeとsudo make installをすれば大丈夫です。
あとはpythonで使うライブラリをpipでインストールすればOKです。
pip install mecab-python3
辞書のmakeがlibmecab.so.2が見つからないとかで失敗したり、
pythonで import MeCab とした時に
ImportError: libmecab.so.2: cannot open shared object file: No such file or directory
とエラーが出た場合には、
基本的には「.profile (場合によりけりで.bashrc)」に以下のように一文を追加してください。
(※libmecab.so.2は/usr/local/libに存在しているはずです)
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
pinebookはいろんなところで躓いて、やっぱりmecabでもつまづきますが大丈夫です。
Pinebook PROで動きます。
Pinephone(mobian)でも使えます。
インテル系じゃないんです。情報がありません。
ちなみにスーパーコンピュータ「富嶽」はARMでも特殊なものなので、一緒にはできません。
スマホとかで使われている低電力消費CPUです。
で、最近では、Mecabという形態素解析のライブラリをインストールしようとした時に躓きました。
Mecabのサイトで配布されているプログラムの一部が古くて、
configure cannot guess build type
という警告が出て止まるのです。
なので、これをarm系CPUでインストールする場合には、一部のファイルを手動で新しいものに更新してあげないとインストールできません(makeが動きません)。
#mecabのフォルダに移動
cd mecab-0.996
#古いファイルを削除
rm config.guess
#ネットを通じて新しいファイルをダウンロード
wget https://raw.githubusercontent.com/gcc-mirror/gcc/master/config.guess
これでmakeできるようになります。
あとはインストールの手順通りに
./configure
make
make check
sudo make install
でインストールできます。
※このほか辞書のインストールも忘れないでください。
tar zxfv mecab-ipadic-2.7.0-XXXX.tar.gz
cd mecab-ipadic-2.7.0-*****(実際にあるフォルダ名にしてください)
./configure --with-charset=utf8
make
sudo make install
※辞書の文字コードはデフォルトがeucなので、utf-8に変更しています。
この部分です。
./configure --with-charset=utf8
もし、makeで文字コードの指定を変えたいときは、make cleanとしてから
./configure --with-charset=utf8
もしくは
./configure --with-charset=sjis
と設定しなおして、makeとsudo make installをすれば大丈夫です。
あとはpythonで使うライブラリをpipでインストールすればOKです。
pip install mecab-python3
辞書のmakeがlibmecab.so.2が見つからないとかで失敗したり、
pythonで import MeCab とした時に
ImportError: libmecab.so.2: cannot open shared object file: No such file or directory
とエラーが出た場合には、
基本的には「.profile (場合によりけりで.bashrc)」に以下のように一文を追加してください。
(※libmecab.so.2は/usr/local/libに存在しているはずです)
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib
pinebookはいろんなところで躓いて、やっぱりmecabでもつまづきますが大丈夫です。
Pinebook PROで動きます。
Pinephone(mobian)でも使えます。
PytorchでHSV画像を扱う(RGB⇒HSV変換) [人工知能(ディープラーニング)]
Pytorchで画像を扱う時、輝度と色情報を分離して、色情報だけを抜き出したり、加工したい時があります。
そもそも一般的なRGBの形式だと、明るさ(輝度情報)と色の情報がRGBの各色情報に含まれているので単純に明るさを変えるとしても、RGBの3つのデータを扱う必要があります。
明るさの変更くらいならばRGBでも良いのですが…例えば、白黒画像をカラーにするとか、色だけを他の画像から持ってきたい、とかの場合には、RGB形式ではとんでもなく複雑な処理が必要になります。
ですがHSV形式のように色相(Hue)、彩度(Saturation・Chroma)、明度(Value・Brightness)で構成される画像だと、色の情報(HとS)と、輝度で作られる画像の情報(V)を別々に取り扱うことが出来ます。
色の情報だけを抜き取って、他の画像に色だけを移し替える事も簡単です。
他にも、白黒画像に色を追加してカラーにしたり、という場合にはRGBではなくて、HSVの方が効率的です。
明るさだけを変える場合には、明度(Value・Brightness)だけを変えれば良くて、色への影響がないのも便利です。
このHSV画像の取り扱いも、torchvisionとPILを組み合わせることで簡単に出来ます。
RGB→HSV変換、HSV→RGB変換も簡単です。
######----- pytorch、ptorchvision、PILのインポート
import torch
import torchvision
from PIL import Image
####画像の読み込み
a=Image.open('NEKO.JPG')
####RGB形式からHSV形式へ変換
neko2=a.convert('HSV')
####HSVのデータをTensor形式のデータに変換
tneko=torchvision.transforms.ToTensor()(neko2)
#これで、tnekoにHSV形式の3次元のTensorに変換されます。
####輝度を半分にしてみる場合にはこんな感じで直接データをいじることが出来ます。
tneko[2]=tneko[2]/2
####HSV形式のPILイメージに変換
neko3=torchvision.transforms.ToPILImage('HSV')(tneko)
####HSVからRGB形式へ変換
rgbneko=neko3.convert('RGB')
####表示してみる
rgbneko.show()
こんな感じで扱えます。
●注意点としては、torchvisionには、RGB画像を扱う、とても似た機能の命令があります。
※こちらを使うと、HSV形式などでの変換が出来ないので注意してください。
###PILイメージからTensorへ変換(RGB)
ttt=torchvision.transforms.functional.to_tensor(a)
###TensorからPILイメージへ変換(RGBのみ)
aa=torchvision.transforms.functional.to_pil_image(ttt)
opencvを使う人もいますが、(おそらく)この方法が簡単です。
そもそも一般的なRGBの形式だと、明るさ(輝度情報)と色の情報がRGBの各色情報に含まれているので単純に明るさを変えるとしても、RGBの3つのデータを扱う必要があります。
明るさの変更くらいならばRGBでも良いのですが…例えば、白黒画像をカラーにするとか、色だけを他の画像から持ってきたい、とかの場合には、RGB形式ではとんでもなく複雑な処理が必要になります。
ですがHSV形式のように色相(Hue)、彩度(Saturation・Chroma)、明度(Value・Brightness)で構成される画像だと、色の情報(HとS)と、輝度で作られる画像の情報(V)を別々に取り扱うことが出来ます。
色の情報だけを抜き取って、他の画像に色だけを移し替える事も簡単です。
他にも、白黒画像に色を追加してカラーにしたり、という場合にはRGBではなくて、HSVの方が効率的です。
明るさだけを変える場合には、明度(Value・Brightness)だけを変えれば良くて、色への影響がないのも便利です。
このHSV画像の取り扱いも、torchvisionとPILを組み合わせることで簡単に出来ます。
RGB→HSV変換、HSV→RGB変換も簡単です。
######----- pytorch、ptorchvision、PILのインポート
import torch
import torchvision
from PIL import Image
####画像の読み込み
a=Image.open('NEKO.JPG')
####RGB形式からHSV形式へ変換
neko2=a.convert('HSV')
####HSVのデータをTensor形式のデータに変換
tneko=torchvision.transforms.ToTensor()(neko2)
#これで、tnekoにHSV形式の3次元のTensorに変換されます。
####輝度を半分にしてみる場合にはこんな感じで直接データをいじることが出来ます。
tneko[2]=tneko[2]/2
####HSV形式のPILイメージに変換
neko3=torchvision.transforms.ToPILImage('HSV')(tneko)
####HSVからRGB形式へ変換
rgbneko=neko3.convert('RGB')
####表示してみる
rgbneko.show()
こんな感じで扱えます。
●注意点としては、torchvisionには、RGB画像を扱う、とても似た機能の命令があります。
※こちらを使うと、HSV形式などでの変換が出来ないので注意してください。
###PILイメージからTensorへ変換(RGB)
ttt=torchvision.transforms.functional.to_tensor(a)
###TensorからPILイメージへ変換(RGBのみ)
aa=torchvision.transforms.functional.to_pil_image(ttt)
opencvを使う人もいますが、(おそらく)この方法が簡単です。
(PYTORCH)torchvision でのimport時のエラー [人工知能(ディープラーニング)]
もし、torchvisionをimport しようとした時に
ImportError: cannot import name 'PILLOW_VERSION' from 'PIL' (/home/lina/anaconda3/lib/python3.7/site-packages/PIL/__init__.py)
というエラーが起きた場合、PILLOWのバージョンが7になっていたりしないか確認してください。
condaでインストールした場合なら
conda list | grep pillow
pip3でインストールした場合なら
pip3 list | grep pillow
で確認してください。
torchvisionはバージョンが7以上だと動かないのです
> conda list | grep pillow
pillow 6.2.1 py37h34e0f95_0
こんな感じで(6.2.1※6.2.1が実質上7未満で最も新しいバージョンです)ならば問題ありません。
もし、7以上になっている場合には、
一旦削除して、バージョン6.2.1をインストールしてください。
アンインストールはそれぞれ
conda remove pillow
もしくは
pip3 uninstall pillow
となります。
その上で、
conda install pillow==6.2.1
もしくは
pip3 install pillow==6.2.1
とバージョン指定をしてインストールすれば、torchvisionも動作するはずです。
※場合によっては、一旦torchvisionをアンインストールして、再度インストールし直す必要があります。
これに気が付かずにだいぶなやんだことがありました…
ImportError: cannot import name 'PILLOW_VERSION' from 'PIL' (/home/lina/anaconda3/lib/python3.7/site-packages/PIL/__init__.py)
というエラーが起きた場合、PILLOWのバージョンが7になっていたりしないか確認してください。
condaでインストールした場合なら
conda list | grep pillow
pip3でインストールした場合なら
pip3 list | grep pillow
で確認してください。
torchvisionはバージョンが7以上だと動かないのです
> conda list | grep pillow
pillow 6.2.1 py37h34e0f95_0
こんな感じで(6.2.1※6.2.1が実質上7未満で最も新しいバージョンです)ならば問題ありません。
もし、7以上になっている場合には、
一旦削除して、バージョン6.2.1をインストールしてください。
アンインストールはそれぞれ
conda remove pillow
もしくは
pip3 uninstall pillow
となります。
その上で、
conda install pillow==6.2.1
もしくは
pip3 install pillow==6.2.1
とバージョン指定をしてインストールすれば、torchvisionも動作するはずです。
※場合によっては、一旦torchvisionをアンインストールして、再度インストールし直す必要があります。
これに気が付かずにだいぶなやんだことがありました…
pytorchで画像を読み込んでTENSORにする他 [人工知能(ディープラーニング)]
PYTORCHを使って画像処理をしようとして、最初に躓くのが画像を読み込んでどうやってtensorに変換するかということです。
torchvisionを使うと、簡単に出来てしまいます。
たとえば、画像(hanio.jpg)を読み込んで、tensorに変換してhanihaniに代入する場合はこんな感じです。
import torch
import torchvision
from PIL import Image
img=Image.open('hanio.jpg')
hanihani=torchvision.transforms.functional.to_tensor(img)
これで、hanihaniというtensorに代入が完了です。
ちなみに、ここで hanihani.show() と打ち込んでも、すでにtensorに変換されているので、エラーとなって表示できません。
エラーはこんな感じです:AttributeError: 'Tensor' object has no attribute 'show'
tensorをもう一度PILイメージに変換する場合には、
hani2=torchvision.transforms.functional.to_pil_image(hanihani)
とすればイメージ形式に変換できます。
hani2.show()
という具合に、show()を使っても大丈夫です。
画像を保存したいならば、
hani2.save('newhanio.jpg')
という感じで保存も出来てしまいます。
実はこんな感じで、TORCHVISIONはいろんな変換機能もあって便利なんです。
データセットのライブラリーだけじゃないんです。
●tensor形式のデータhanihaniを画像として保存する場合には、
torchvision.utils.save_image(hanihani,'newconthani.jpg')
これで、tensor形式のデータをそのまま保存できるので便利です。
詳しくはhttps://pytorch.org/docs/stable/torchvision/transforms.htmlの下の方に書かれています。
たとえば、tensorに代入しなくとも、上下反転なんかならば、
(imgはPILイメージかnumpy配列です)
hani2=torchvision.transforms.functional.vflip(img)
これで完了です。
●カラーを白黒のグレースケール画像に変換するなら、
hani2=torchvision.transforms.functional.to_grayscale(img)
●画像を任意の角度で傾けるならば(たとえば45度なら)
hani2=torchvision.transforms.functional.rotate(img,45)
●画像のリサイズ(縦合わせ)ならば
hani2=torchvision.transforms.functional.resize(img,300)
※画像の縦を300の画像としてリサイズ
●画像の一部の切りぬきならば
hani2=torchvision.transforms.functional.crop(img,20,0,300,200)
※画像の縦20,横0を始点として、高さ300,横幅200で画像を切り抜き
●画像の一部を切り抜いてリサイズするなら
hani2=torchvision.transforms.functional.resized_crop(img,20,0,300,200,500)
※画像の縦20,横0を始点として、高さ300,横幅200で画像を切り抜き、縦の長さを500ピクセルとしてリサイズ
●画像のコントラストを変更
hani2=torchvision.transforms.functional.adjust_contrast(img,1.5)
パラメーターは0〜2で。1がオリジナルで、0方向はコントラストが低く、1以上がコントラストが強くなります。
●画像の色相を変更
hani2=torchvision.transforms.functional.adjust_hue(img,0.2)
パラメーターは−0.5 〜 0.5で。
torchvisionは便利です。
ちなみに、この文章もJETSON nanoで作成していたりします。JETSON nano
面白いですよ。
ちなみにこのPYTORCHの記事はJETSONだけでなく普通のPCでも同じです。
windowsでもmacでもLINUXでも同じです。
torchvisionを使うと、簡単に出来てしまいます。
たとえば、画像(hanio.jpg)を読み込んで、tensorに変換してhanihaniに代入する場合はこんな感じです。
import torch
import torchvision
from PIL import Image
img=Image.open('hanio.jpg')
hanihani=torchvision.transforms.functional.to_tensor(img)
これで、hanihaniというtensorに代入が完了です。
ちなみに、ここで hanihani.show() と打ち込んでも、すでにtensorに変換されているので、エラーとなって表示できません。
エラーはこんな感じです:AttributeError: 'Tensor' object has no attribute 'show'
tensorをもう一度PILイメージに変換する場合には、
hani2=torchvision.transforms.functional.to_pil_image(hanihani)
とすればイメージ形式に変換できます。
hani2.show()
という具合に、show()を使っても大丈夫です。
画像を保存したいならば、
hani2.save('newhanio.jpg')
という感じで保存も出来てしまいます。
実はこんな感じで、TORCHVISIONはいろんな変換機能もあって便利なんです。
データセットのライブラリーだけじゃないんです。
●tensor形式のデータhanihaniを画像として保存する場合には、
torchvision.utils.save_image(hanihani,'newconthani.jpg')
これで、tensor形式のデータをそのまま保存できるので便利です。
詳しくはhttps://pytorch.org/docs/stable/torchvision/transforms.htmlの下の方に書かれています。
たとえば、tensorに代入しなくとも、上下反転なんかならば、
(imgはPILイメージかnumpy配列です)
hani2=torchvision.transforms.functional.vflip(img)
これで完了です。
●カラーを白黒のグレースケール画像に変換するなら、
hani2=torchvision.transforms.functional.to_grayscale(img)
●画像を任意の角度で傾けるならば(たとえば45度なら)
hani2=torchvision.transforms.functional.rotate(img,45)
●画像のリサイズ(縦合わせ)ならば
hani2=torchvision.transforms.functional.resize(img,300)
※画像の縦を300の画像としてリサイズ
●画像の一部の切りぬきならば
hani2=torchvision.transforms.functional.crop(img,20,0,300,200)
※画像の縦20,横0を始点として、高さ300,横幅200で画像を切り抜き
●画像の一部を切り抜いてリサイズするなら
hani2=torchvision.transforms.functional.resized_crop(img,20,0,300,200,500)
※画像の縦20,横0を始点として、高さ300,横幅200で画像を切り抜き、縦の長さを500ピクセルとしてリサイズ
●画像のコントラストを変更
hani2=torchvision.transforms.functional.adjust_contrast(img,1.5)
パラメーターは0〜2で。1がオリジナルで、0方向はコントラストが低く、1以上がコントラストが強くなります。
●画像の色相を変更
hani2=torchvision.transforms.functional.adjust_hue(img,0.2)
パラメーターは−0.5 〜 0.5で。
torchvisionは便利です。
ちなみに、この文章もJETSON nanoで作成していたりします。JETSON nano
面白いですよ。
ちなみにこのPYTORCHの記事はJETSONだけでなく普通のPCでも同じです。
windowsでもmacでもLINUXでも同じです。
(補足)JETSON NANOにPYTORCHをインストール [人工知能(ディープラーニング)]
※2019/07/14にNVIDIAのPYTHORCHに関する公式ページを見たところ
情報が更新されていたので、インストール方法を補足しつつ説明します。
印象としては、以前よりも簡単になった気もします。
以下の方法でなんらかのエラーなどが起きた場合には、公式サイトの情報をチェックしてください。
※基本的に2019年5月の補足情報と同じです。
2019/07/14時点での公式サイトはこちらです。
https://devtalk.nvidia.com/default/topic/1049071/jetson-nano/pytorch-for-jetson-nano-with-new-torch2trt-converter/
nVIDIAの公式サイトの情報は、結構な頻度で変わっています。
私がインストールしたときには、 libjpeg-devの情報は記載されていませんでしたが、現在は記載されています。
抜粋すると、以下のようになります。
●python3.6にpytorch1.1をインストールする
WGETとPIP3でインストールします。
wget https://nvidia.box.com/shared/static/j2dn48btaxosqp0zremqqm8pjelriyvs.whl -O torch-1.1.0-cp36-cp36m-linux_aarch64.whl
pip3 install numpy torch-1.1.0-cp36-cp36m-linux_aarch64.whl
●torch visionをインストール
(1)まず画像等の変換作業に必要な他の関連するライブラリーをインストール
sudo apt-get install libjpeg-dev zlib1g-dev
(2)必要なファイルを、torchvisonというフォルダーを作成してgitでダウンロードする
git clone -b v0.3.0 https://github.com/pytorch/vision torchvision
(3)torchvisionのフォルダーに移動
cd torchvision
(4)Python3で設定ファイルを読み込ませて実行(実質的なインストール作業)する
sudo python3 setup.py install
(※公式サイトでは、「python3」ではなく、ver2.7である「python」と記載されていますが、それだとpython3を使う場合には不整合が起こると思います)
")
このアクリルケース意外と良いです。ただ、組み立ての説明書はないため、仮組みしてどのアクリル板がどこにはまるのかを調べる必要がありますのでご注意ください。
情報が更新されていたので、インストール方法を補足しつつ説明します。
印象としては、以前よりも簡単になった気もします。
以下の方法でなんらかのエラーなどが起きた場合には、公式サイトの情報をチェックしてください。
※基本的に2019年5月の補足情報と同じです。
2019/07/14時点での公式サイトはこちらです。
https://devtalk.nvidia.com/default/topic/1049071/jetson-nano/pytorch-for-jetson-nano-with-new-torch2trt-converter/
nVIDIAの公式サイトの情報は、結構な頻度で変わっています。
私がインストールしたときには、 libjpeg-devの情報は記載されていませんでしたが、現在は記載されています。
抜粋すると、以下のようになります。
●python3.6にpytorch1.1をインストールする
WGETとPIP3でインストールします。
wget https://nvidia.box.com/shared/static/j2dn48btaxosqp0zremqqm8pjelriyvs.whl -O torch-1.1.0-cp36-cp36m-linux_aarch64.whl
pip3 install numpy torch-1.1.0-cp36-cp36m-linux_aarch64.whl
●torch visionをインストール
(1)まず画像等の変換作業に必要な他の関連するライブラリーをインストール
sudo apt-get install libjpeg-dev zlib1g-dev
(2)必要なファイルを、torchvisonというフォルダーを作成してgitでダウンロードする
git clone -b v0.3.0 https://github.com/pytorch/vision torchvision
(3)torchvisionのフォルダーに移動
cd torchvision
(4)Python3で設定ファイルを読み込ませて実行(実質的なインストール作業)する
sudo python3 setup.py install
(※公式サイトでは、「python3」ではなく、ver2.7である「python」と記載されていますが、それだとpython3を使う場合には不整合が起こると思います)
NVIDIA Jetson Nano開発者キットケース用の新しい到着アクリルケースボックス(ジャストボックス)
- 出版社/メーカー: heartbeeps
- メディア: エレクトロニクス
このアクリルケース意外と良いです。ただ、組み立ての説明書はないため、仮組みしてどのアクリル板がどこにはまるのかを調べる必要がありますのでご注意ください。
JETSON NANOにPYTORCHをインストール [人工知能(ディープラーニング)]
NVIDIAからワンボードの人工知能開発用ボード「JETSON NANO」が発売されました。
お値段13000円くらいで、販売が終了したTK1よりも高性能です。しかも安い!!
TK1だとセッティングのためにはUBUNTUが動作する母艦PCが必要だったんですが、NANOには必要ありません。単純なワンボードPCとしても性能は悪くないですし、すごいヤツです。
おかげで、これまでGPU演算ライブラリを使って人工知能を勉強しようと思ってもそれなりに敷居は高かったのですが、ずいぶん低くなりました。
で、私が使っていた人工知能フレームワークtorchもメンテナンス状態ということで新しい機能の追加はストップしていますので、Pytorchに移行することにしました。
※7月時点での補足があります!!
7月に追加した情報も読んでからインストールしてください!!!
◆Pytorchのインストール前の準備
最初にPIP3とgitを使えるようにする
sudo apt install python3-pip git
※注意:この他にもPytorchのインストールに必要なライブラリが抜けているかもしれません。
適宜必要なライブラリをインストールしてください。
◆Pytorchのインストール手順
各種ファイルのアーカイブファイルのダウンロードをする
wget https://nvidia.box.com/shared/static/veo87trfaawj5pfwuqvhl6mzc5b55fbj.whl -O torch-1.1.0a0+b457266-cp36-cp36m-linux_aarch64.whl
Python3で使えるようにインストールする
pip3 install numpy torch-1.1.0a0+b457266-cp36-cp36m-linux_aarch64.whl
これで、python3からPytorchが使えるようになるはずです。
以下のテストプログラムを実行して問題なければPytorchはインスールされています。
import torch
print(torch.__version__)
print('CUDA available: ' + str(torch.cuda.is_available()))
a = torch.cuda.FloatTensor(2).zero_()
print('Tensor a = ' + str(a))
b = torch.randn(2).cuda()
print('Tensor b = ' + str(b))
c = a + b
print('Tensor c = ' + str(c))
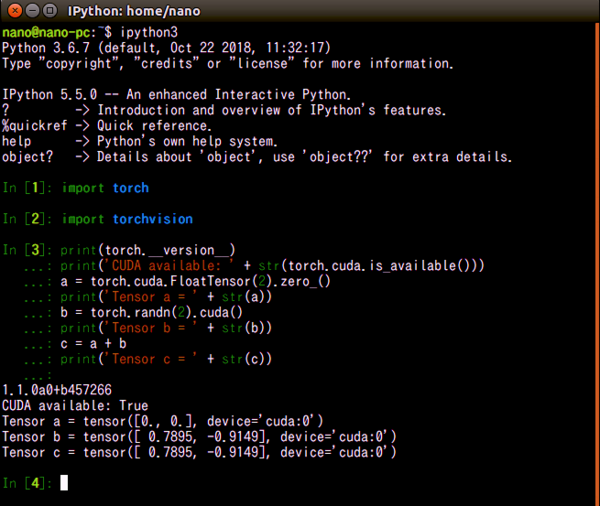
画像では自分が使いやすいようにIpyhon3をインストールして、そこからPython3を使っています。
人工知能フレームワークの勉強で数値データをメインに扱うだけならここまででも大丈夫ですが、やはりそれでは物足りなくなります。データセットの入手や画像処理ができるtorchvisionもインストールしましょう。
torchvisionをインストールしないとJPEG画像を読み込んで、そこからtensorに一気に変換したりということが出来ません。いちいちnumpyやらを経由させる必要が出てきて面倒になりますので、画像処理をやってみたい人はtorchvisionのインストールは必須です。
●torchvisionのインストール
インストール用ファイルのダウンロード
git clone https://github.com/pytorch/vision
ダウンロードしたディレクトリに移動
cd vision
python3へインストール実行
sudo python3 setup.py install
これで、エラーが出なければ良いのですが私の場合にはエラーが出たんです。
torchvisionは、Pillowに入っているPILを使います。Pillowを使えるようにしないと、画像処理の便利なコマンドが使えません。しかもpip3 install pillow --userとかやってもインストールできなかったりします。
そんなときには
sudo apt-get install libjpeg-dev
として、jpeg関係のライブラリをインストールしてください。
pillowは外部の画像処理ライブラリを呼び出しているので、それがないと動かないのです。
これでpython3を起動して、import torchvisionとしてエラーが出なければ大丈夫です。
参考URL
NVIDIAの公式サイト
https://devtalk.nvidia.com/default/topic/1049071/pytorch-for-jetson-nano/
======================
●2019/07/14 補足
nVIDIAの公式サイトの情報は、結構な頻度で変わっています。
私がインストールしたときには、 libjpeg-devの情報は記載されていませんでしたが、現在は記載されています。
抜粋すると、以下のようになります。
●python3.6にpytorch1.1をインストールする
WGETとPIP3でインストールします。
wget https://nvidia.box.com/shared/static/j2dn48btaxosqp0zremqqm8pjelriyvs.whl -O torch-1.1.0-cp36-cp36m-linux_aarch64.whl
pip3 install numpy torch-1.1.0-cp36-cp36m-linux_aarch64.whl
●torch visionをインストール
(1)まず画像等の変換作業に必要な他の関連するライブラリーをインストール
sudo apt-get install libjpeg-dev zlib1g-dev
(2)必要なファイルを、torchvisonというフォルダーを作成してgitでダウンロードする
git clone -b v0.3.0 https://github.com/pytorch/vision torchvision
(3)torchvisionのフォルダーに移動
cd torchvision
(4)Python3で設定ファイルを読み込ませて実行(実質的なインストール作業)する
sudo python3 setup.py install
(※公式サイトでは、「python3」ではなく、ver2.7である「python」と記載されていますが、それだとpython3を使う場合には不整合が起こると思います)
お値段13000円くらいで、販売が終了したTK1よりも高性能です。しかも安い!!
TK1だとセッティングのためにはUBUNTUが動作する母艦PCが必要だったんですが、NANOには必要ありません。単純なワンボードPCとしても性能は悪くないですし、すごいヤツです。
おかげで、これまでGPU演算ライブラリを使って人工知能を勉強しようと思ってもそれなりに敷居は高かったのですが、ずいぶん低くなりました。
で、私が使っていた人工知能フレームワークtorchもメンテナンス状態ということで新しい機能の追加はストップしていますので、Pytorchに移行することにしました。
※7月時点での補足があります!!
7月に追加した情報も読んでからインストールしてください!!!
◆Pytorchのインストール前の準備
最初にPIP3とgitを使えるようにする
sudo apt install python3-pip git
※注意:この他にもPytorchのインストールに必要なライブラリが抜けているかもしれません。
適宜必要なライブラリをインストールしてください。
◆Pytorchのインストール手順
各種ファイルのアーカイブファイルのダウンロードをする
wget https://nvidia.box.com/shared/static/veo87trfaawj5pfwuqvhl6mzc5b55fbj.whl -O torch-1.1.0a0+b457266-cp36-cp36m-linux_aarch64.whl
Python3で使えるようにインストールする
pip3 install numpy torch-1.1.0a0+b457266-cp36-cp36m-linux_aarch64.whl
これで、python3からPytorchが使えるようになるはずです。
以下のテストプログラムを実行して問題なければPytorchはインスールされています。
import torch
print(torch.__version__)
print('CUDA available: ' + str(torch.cuda.is_available()))
a = torch.cuda.FloatTensor(2).zero_()
print('Tensor a = ' + str(a))
b = torch.randn(2).cuda()
print('Tensor b = ' + str(b))
c = a + b
print('Tensor c = ' + str(c))

画像では自分が使いやすいようにIpyhon3をインストールして、そこからPython3を使っています。
人工知能フレームワークの勉強で数値データをメインに扱うだけならここまででも大丈夫ですが、やはりそれでは物足りなくなります。データセットの入手や画像処理ができるtorchvisionもインストールしましょう。
torchvisionをインストールしないとJPEG画像を読み込んで、そこからtensorに一気に変換したりということが出来ません。いちいちnumpyやらを経由させる必要が出てきて面倒になりますので、画像処理をやってみたい人はtorchvisionのインストールは必須です。
●torchvisionのインストール
インストール用ファイルのダウンロード
git clone https://github.com/pytorch/vision
ダウンロードしたディレクトリに移動
cd vision
python3へインストール実行
sudo python3 setup.py install
これで、エラーが出なければ良いのですが私の場合にはエラーが出たんです。
torchvisionは、Pillowに入っているPILを使います。Pillowを使えるようにしないと、画像処理の便利なコマンドが使えません。しかもpip3 install pillow --userとかやってもインストールできなかったりします。
そんなときには
sudo apt-get install libjpeg-dev
として、jpeg関係のライブラリをインストールしてください。
pillowは外部の画像処理ライブラリを呼び出しているので、それがないと動かないのです。
これでpython3を起動して、import torchvisionとしてエラーが出なければ大丈夫です。
参考URL
NVIDIAの公式サイト
https://devtalk.nvidia.com/default/topic/1049071/pytorch-for-jetson-nano/
======================
●2019/07/14 補足
nVIDIAの公式サイトの情報は、結構な頻度で変わっています。
私がインストールしたときには、 libjpeg-devの情報は記載されていませんでしたが、現在は記載されています。
抜粋すると、以下のようになります。
●python3.6にpytorch1.1をインストールする
WGETとPIP3でインストールします。
wget https://nvidia.box.com/shared/static/j2dn48btaxosqp0zremqqm8pjelriyvs.whl -O torch-1.1.0-cp36-cp36m-linux_aarch64.whl
pip3 install numpy torch-1.1.0-cp36-cp36m-linux_aarch64.whl
●torch visionをインストール
(1)まず画像等の変換作業に必要な他の関連するライブラリーをインストール
sudo apt-get install libjpeg-dev zlib1g-dev
(2)必要なファイルを、torchvisonというフォルダーを作成してgitでダウンロードする
git clone -b v0.3.0 https://github.com/pytorch/vision torchvision
(3)torchvisionのフォルダーに移動
cd torchvision
(4)Python3で設定ファイルを読み込ませて実行(実質的なインストール作業)する
sudo python3 setup.py install
(※公式サイトでは、「python3」ではなく、ver2.7である「python」と記載されていますが、それだとpython3を使う場合には不整合が起こると思います)
torch7:CSVでファイル保存 [人工知能(ディープラーニング)]
データをファイルとして保存するときにいろいろと方法はあるのですが、CSVファイルとして保存するのは意外と面倒だったりします。
例えば、以下のような単純な10x10の二次元配列をファイルとして保存するだけでも結構面倒です。
--------------------------------------
1 6 8 2 1 7 4 4 9 7
6 9 7 3 8 9 0 9 8 0
8 2 4 6 2 7 8 4 7 7
7 6 9 1 7 2 3 8 1 9
2 4 6 7 5 5 1 5 6 6
8 9 2 3 6 1 7 8 5 0
0 3 4 5 7 4 2 0 8 6
9 6 5 1 3 8 5 9 3 8
0 9 8 9 5 4 5 8 4 2
1 3 5 3 2 1 7 7 4 2
[torch.DoubleTensor of size 10x10]
--------------------------------------
こんな時は、以前の「パターン認識」でも紹介したcsvigoを使えば簡単です。
(今回はコマンドラインで直接動かしていますが、プログラムとしてファイルに保存しても動作はできます)
基本的にはこれだけです。
require 'csvigo'
a=torch.Tensor(10,10):random(0,9)
b=torch.totable(a)
csvigo.save{data=b,path='test.csv'}
解説すると…
-- csvigoライブラリーを読み込む
require 'csvigo'
-- 10x10の数値(Tensor)を乱数で作る
a=torch.Tensor(10,10):random(0,9)
-- torch.Tensor形式のaを、テーブル形式でbにセットする
b=torch.totable(a)
-- csvigo.saveを使って、ファイルとしてむ保存
-- 「data=」に続いてテーブルの変数、「path='ファイル名'」をつけます
-- カッコ()ではなく、{ }を使ってください。
csvigo.save{data=b,path='test.csv'}
たったこれだけです。
これでCSVファイルとして保存できます。
ただし、ここで注意するポイントがあります。
単純に
1
8
5
6
7
4
1
3
6
8
のようにファイルを出力したい場合、Tensorは
th> a
1
8
5
6
7
4
1
3
6
8
[torch.DoubleTensor of size 10]と単純な10個の配列を元にして、保存用テーブルのデータを作ってcsvigoライブラリで保存しようとしてもエラーになってしまいます。
具体的にはテーブルの変数 b
{
1 : 1
2 : 8
3 : 5
4 : 6
5 : 7
6 : 4
7 : 1
8 : 3
9 : 6
10 : 8
}
*このデータをcsvigoで保存しようするとエラーになります。
このような場合には、
-- まずは10個の配列を 1x10に直して
a=a:repeatTensor(a,1,1)
-- それを10x1に「t()」で行と列を入れ替えた配列に直して
a=a:t()
-- テーブル形式に変換します
a=torch.totable(a)
という感じで、10x1の配列(テンソル)としてデータに直して、それをテーブルに変換する必要があります。(もっとスマートな方法があるかもしれません)
th> a
9
6
9
8
7
9
1
4
1
8
[torch.DoubleTensor of size 10x1]
これが最終的には…
th> b
{
1 :
{
1 : 9
}
2 :
{
1 : 6
}
3 :
{
1 : 9
}
4 :
{
1 : 8
}
5 :
{
1 : 7
}
6 :
{
1 : 9
}
7 :
{
1 : 1
}
8 :
{
1 : 4
}
9 :
{
1 : 1
}
10 :
{
1 : 8
}
}
こんな形になります。
これであれば縦に数字が並んだCSVファイルが作成できます。
th> csvigo.save{path='ttt.csv',data=b}
<csv> writing to file: ttt.csv
<csv> writing done
これでもうCSVファイルでの保存ができるのでいろいろと利用範囲が広がります。
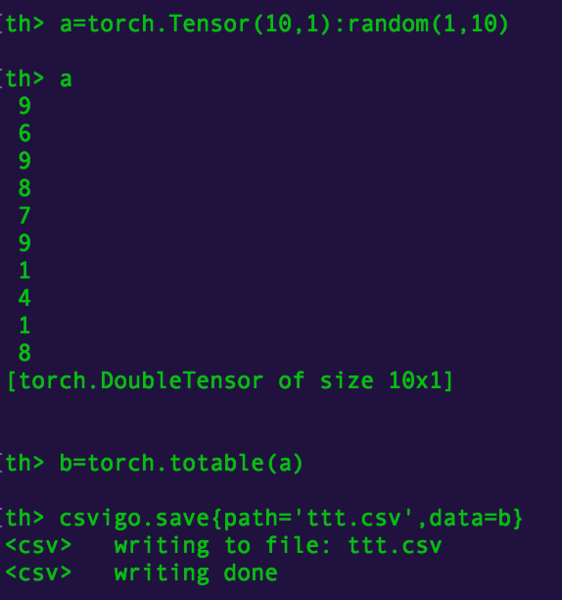
(CSVでの保存例)
例えば、以下のような単純な10x10の二次元配列をファイルとして保存するだけでも結構面倒です。
--------------------------------------
1 6 8 2 1 7 4 4 9 7
6 9 7 3 8 9 0 9 8 0
8 2 4 6 2 7 8 4 7 7
7 6 9 1 7 2 3 8 1 9
2 4 6 7 5 5 1 5 6 6
8 9 2 3 6 1 7 8 5 0
0 3 4 5 7 4 2 0 8 6
9 6 5 1 3 8 5 9 3 8
0 9 8 9 5 4 5 8 4 2
1 3 5 3 2 1 7 7 4 2
[torch.DoubleTensor of size 10x10]
--------------------------------------
こんな時は、以前の「パターン認識」でも紹介したcsvigoを使えば簡単です。
(今回はコマンドラインで直接動かしていますが、プログラムとしてファイルに保存しても動作はできます)
基本的にはこれだけです。
require 'csvigo'
a=torch.Tensor(10,10):random(0,9)
b=torch.totable(a)
csvigo.save{data=b,path='test.csv'}
解説すると…
-- csvigoライブラリーを読み込む
require 'csvigo'
-- 10x10の数値(Tensor)を乱数で作る
a=torch.Tensor(10,10):random(0,9)
-- torch.Tensor形式のaを、テーブル形式でbにセットする
b=torch.totable(a)
-- csvigo.saveを使って、ファイルとしてむ保存
-- 「data=」に続いてテーブルの変数、「path='ファイル名'」をつけます
-- カッコ()ではなく、{ }を使ってください。
csvigo.save{data=b,path='test.csv'}
たったこれだけです。
これでCSVファイルとして保存できます。
ただし、ここで注意するポイントがあります。
単純に
1
8
5
6
7
4
1
3
6
8
のようにファイルを出力したい場合、Tensorは
th> a
1
8
5
6
7
4
1
3
6
8
[torch.DoubleTensor of size 10]と単純な10個の配列を元にして、保存用テーブルのデータを作ってcsvigoライブラリで保存しようとしてもエラーになってしまいます。
具体的にはテーブルの変数 b
{
1 : 1
2 : 8
3 : 5
4 : 6
5 : 7
6 : 4
7 : 1
8 : 3
9 : 6
10 : 8
}
*このデータをcsvigoで保存しようするとエラーになります。
このような場合には、
-- まずは10個の配列を 1x10に直して
a=a:repeatTensor(a,1,1)
-- それを10x1に「t()」で行と列を入れ替えた配列に直して
a=a:t()
-- テーブル形式に変換します
a=torch.totable(a)
という感じで、10x1の配列(テンソル)としてデータに直して、それをテーブルに変換する必要があります。(もっとスマートな方法があるかもしれません)
th> a
9
6
9
8
7
9
1
4
1
8
[torch.DoubleTensor of size 10x1]
これが最終的には…
th> b
{
1 :
{
1 : 9
}
2 :
{
1 : 6
}
3 :
{
1 : 9
}
4 :
{
1 : 8
}
5 :
{
1 : 7
}
6 :
{
1 : 9
}
7 :
{
1 : 1
}
8 :
{
1 : 4
}
9 :
{
1 : 1
}
10 :
{
1 : 8
}
}
こんな形になります。
これであれば縦に数字が並んだCSVファイルが作成できます。
th> csvigo.save{path='ttt.csv',data=b}
<csv> writing to file: ttt.csv
<csv> writing done
これでもうCSVファイルでの保存ができるのでいろいろと利用範囲が広がります。
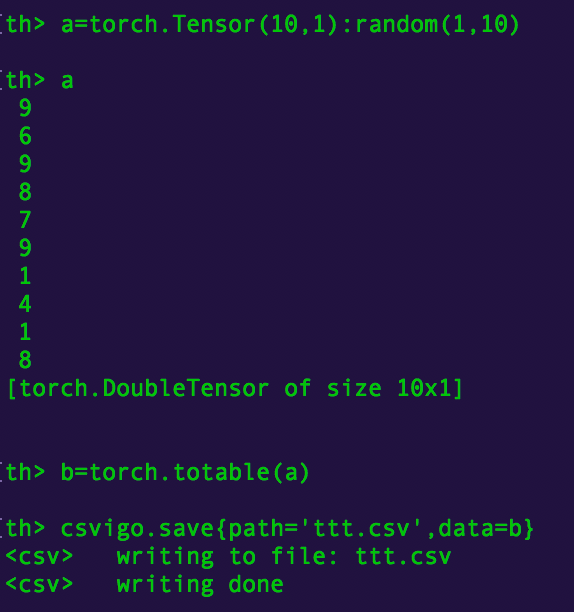
(CSVでの保存例)
torch7のバリエーションcl-torchはおススメできません [人工知能(ディープラーニング)]
torch7のバリエーションには、open-clで処理をGPUに割り当てるものもあります。
cl-torchとか、distro-clとか呼ばれているものですが…オススメできません。
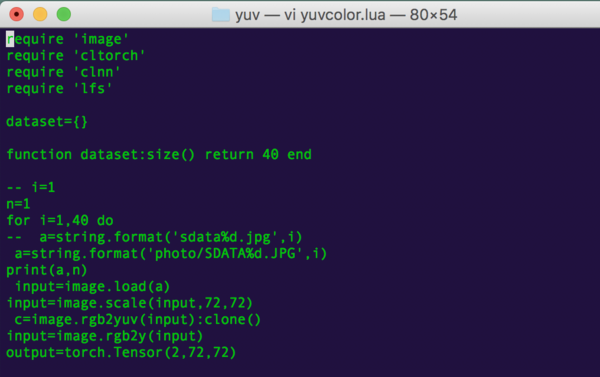
(プログラムのライブラリにclnnやcltorchが含まれているcl-torch動作版のプログラム)
導入してみたのですが…すごく遅いのです。
MacBook Pro (15インチ, 2016)、GPUにRadeon Pro 460を搭載しているモデルでも、下手にOpen-CLなど使わずにCPUで処理した方が早かったほどです。
最初はCPUのパワーを使わずに動いていて、「お、これはいけるか?」と喜んだのですが…
JETSON TK1の5倍もの時間がかかります。(JETSON TK1(CUDA動作)で40秒で終わる処理が、cl-Torchでは200秒以上かかります)
まさかと思って、CPUで動作させると、同じ処理に40秒…しかかかりませんでした。
しかも、別のLINUXのTorch7で作成した人工知能データを読み込ませると、エラーで動作しないというおまけつきです。
発想は良かったのですが…中身が付いてきてませんでした。
CUDAが使えないパソコンの救世主に見えて、実は見掛け倒しという悲しい運命を背負ってしまったようです。
さっそく、cl-Torchは、コマンドラインからさっくり「rm -rf cl-torch」で削除して、通常版のtorch7をインストールしました。
それにしても、2016年のMACBOOK PROはCPU動作でもJETSON TK1のCUDA動作に負けない性能になっていたんですね。
2012年モデルのMAC MINIはTK1にかなり大差で負けてしまうのですが。
(3万円のJETSON TK1が大健闘していると言えるかもしれません)
結論としては、cl-torchはお勧めできません。
なにせ、正式なtorch7で作成した人工知能モデルがエラーで動かないのは致命的です。
cl-torchとか、distro-clとか呼ばれているものですが…オススメできません。
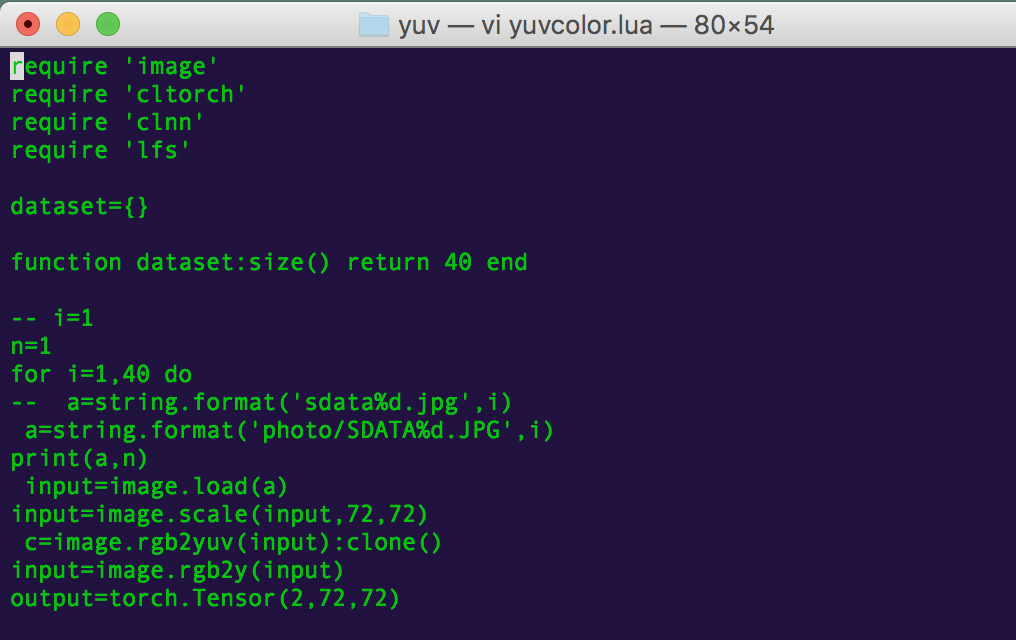
(プログラムのライブラリにclnnやcltorchが含まれているcl-torch動作版のプログラム)
導入してみたのですが…すごく遅いのです。
MacBook Pro (15インチ, 2016)、GPUにRadeon Pro 460を搭載しているモデルでも、下手にOpen-CLなど使わずにCPUで処理した方が早かったほどです。
最初はCPUのパワーを使わずに動いていて、「お、これはいけるか?」と喜んだのですが…
JETSON TK1の5倍もの時間がかかります。(JETSON TK1(CUDA動作)で40秒で終わる処理が、cl-Torchでは200秒以上かかります)
まさかと思って、CPUで動作させると、同じ処理に40秒…しかかかりませんでした。
しかも、別のLINUXのTorch7で作成した人工知能データを読み込ませると、エラーで動作しないというおまけつきです。
発想は良かったのですが…中身が付いてきてませんでした。
CUDAが使えないパソコンの救世主に見えて、実は見掛け倒しという悲しい運命を背負ってしまったようです。
さっそく、cl-Torchは、コマンドラインからさっくり「rm -rf cl-torch」で削除して、通常版のtorch7をインストールしました。
それにしても、2016年のMACBOOK PROはCPU動作でもJETSON TK1のCUDA動作に負けない性能になっていたんですね。
2012年モデルのMAC MINIはTK1にかなり大差で負けてしまうのですが。
(3万円のJETSON TK1が大健闘していると言えるかもしれません)
結論としては、cl-torchはお勧めできません。
なにせ、正式なtorch7で作成した人工知能モデルがエラーで動かないのは致命的です。
torch7で小さくディープラーニング(6)パターン認識 [人工知能(ディープラーニング)]
今回はパターン認識をしてみます。
さらには、これまではプログラムの中で学習用データを作成していましたが、外部のデータを読み込んで処理をします。
まずは、以下のテキストデータをNUMBERS.CSVとしてセーブします。
========================= CSV FILEここの下から
1,1,1,1,0,1,1,0,1,1,0,1,1,1,1,0
0,1,0,0,1,0,0,1,0,0,1,0,0,1,0,1
1,1,1,0,0,1,1,1,1,1,0,0,1,1,1,2
1,1,1,0,0,1,1,1,1,0,0,1,1,1,1,3
1,0,1,1,0,1,1,1,1,0,0,1,0,0,1,4
1,1,1,1,0,0,1,1,1,0,0,1,1,1,1,5
1,1,1,1,0,0,1,1,1,1,0,1,1,1,1,6
1,1,1,0,0,1,0,0,1,0,0,1,0,0,1,7
1,1,1,1,0,1,1,1,1,1,0,1,1,1,1,8
1,1,1,1,0,1,1,1,1,0,0,1,0,0,1,9
========================= CSV FILEここの上まで
実はこのデータ、縦5、横3のピクセルで数字の0〜9を表しています。
例えば数字の9ならば以下のような形です。
===9===
1 1 1
1 0 1
1 1 1
0 0 1
0 0 1
=======
(数字の1が9の形に並んでいます)
これを横一列に並べれば、数字の9は…
1,1,1,1,0,1,1,1,1,0,0,1,0,0,1
というデータになります。
さらに、データを入れたCSVファイルの各行のいちばん右側の数字は、データに対する答えです。
こんな形で0〜9に対応するデータを用意し、それをニューラル・ネットワークで認識できるようにします。
※なお、torch7でCSVファイルを扱えるように、csvigoライブラリーをインストールしておく必要があります。
「luarocks install csvigo」でインストールしてください。
CSVファイルから読み込んだデータは、そのままでは行列データのtorch.Tensorではなく、連想配列といわれるテーブル形式なので、「1」という数字も実際にはテキストの「1」扱いになっているので、それを数値に変えてあげる作業が必要です。
で、パターン認識のプログラムは以下のようになります。
=====================================ここから
require 'nn'
require 'csvigo'
-- ####”luarocks install csvigo” でインストールしておいてください
-- CSVファイルのデータをロード
m=csvigo.load{path='NUMBERS.CSV',mode='large'}
print ("####### DATA LOAD! ######")
dataset={}
function dataset:size() return 10 end
-- 読み込んだデータをtorch.Tensorに直して学習出来るようにする。
for i=1,dataset:size() do
input =torch.Tensor(15)
output=torch.Tensor(10):zero()
input[1]=m[i][1]
input[2]=m[i][2]
input[3]=m[i][3]
input[4]=m[i][4]
input[5]=m[i][5]
input[6]=m[i][6]
input[7]=m[i][7]
input[8]=m[i][8]
input[9]=m[i][9]
input[10]=m[i][10]
input[11]=m[i][11]
input[12]=m[i][12]
input[13]=m[i][13]
input[14]=m[i][14]
input[15]=m[i][15]
a=m[i][16]
-- 10チャンネルの出力のうち、答えになるところを1に設定する
-- Torchの配列などは0スタートではなく、1がスタートになるので注意!
output[a+1]=1
dataset[i]={input,output}
print("###########",m[i][16])
print(input[1],input[2],input[3])
print(input[4],input[5],input[6])
print(input[7],input[8],input[9])
print(input[10],input[11],input[12])
print(input[13],input[14],input[15])
end
print ("####### DATASET! ######")
model=nn.Sequential();
model:add(nn.Linear(15,15))
model:add(nn.Tanh())
model:add(nn.Linear(15,30))
model:add(nn.Tanh())
model:add(nn.Linear(30,10))
-- 今回はソフトマックスも入れてみますが、これがなくともそれぞれの合計が1にならないだけで、順序そのものが入れ替わるなどの変化はありません
model:add(nn.SoftMax())
print ("####### MODEL SET OK! ######")
criterion = nn.MSECriterion()
trainer=nn.StochasticGradient(model,criterion)
trainer.learningRate=0.01
trainer.maxIteration=10000
print ("####### TARINER SET! ######")
trainer:train(dataset)
print ("####### LEARNING...DONE! ######")
-- 学習結果の検証
for i=1,dataset:size() do
input =torch.Tensor(15)
input[1]=m[i][1]
input[2]=m[i][2]
input[3]=m[i][3]
input[4]=m[i][4]
input[5]=m[i][5]
input[6]=m[i][6]
input[7]=m[i][7]
input[8]=m[i][8]
input[9]=m[i][9]
input[10]=m[i][10]
input[11]=m[i][11]
input[12]=m[i][12]
input[13]=m[i][13]
input[14]=m[i][14]
input[15]=m[i][15]
a=model:forward(input)
print ("#############CHECK!",i-1)
print (input:reshape(input,5,3),a)
end
=====================================ここまで
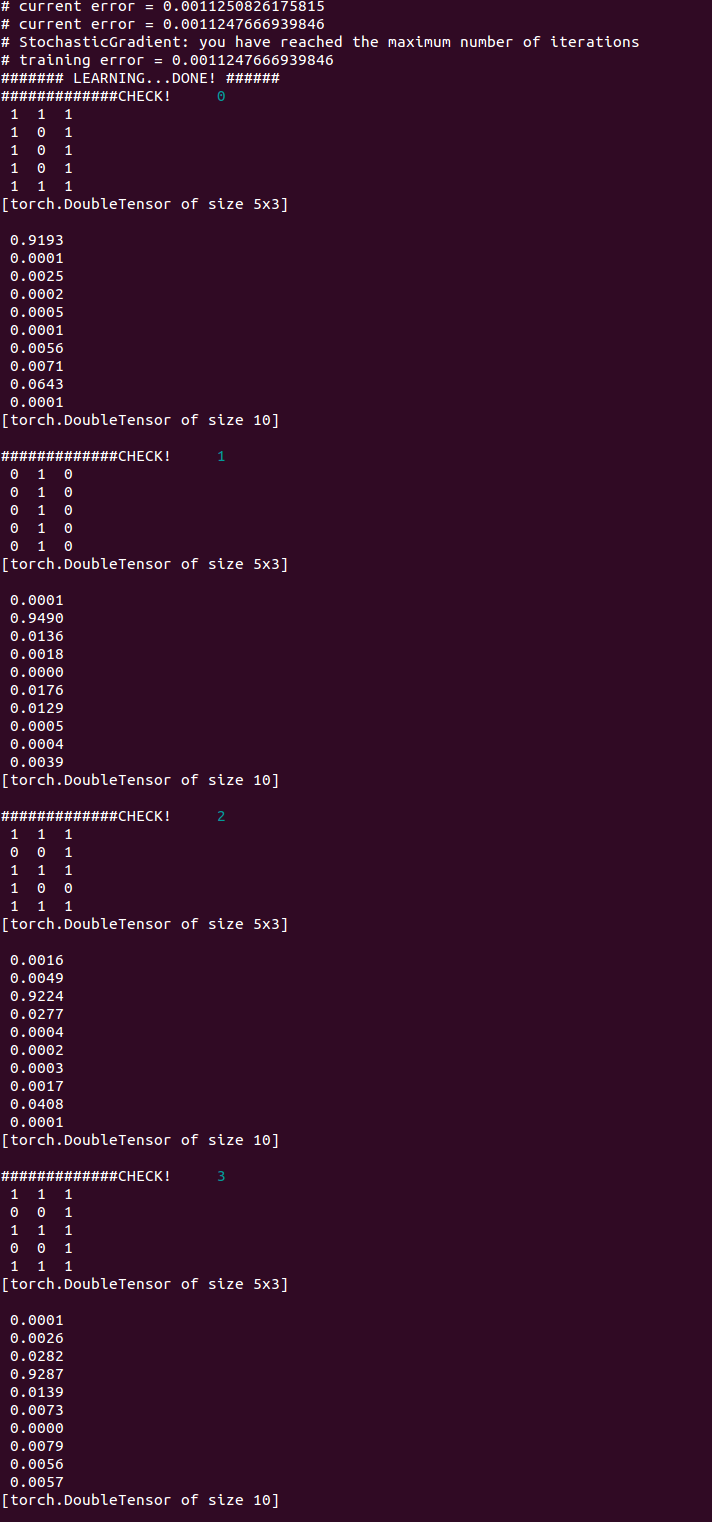
これをファイルに保存し、dofile 'ファイル名'で実行をすると…
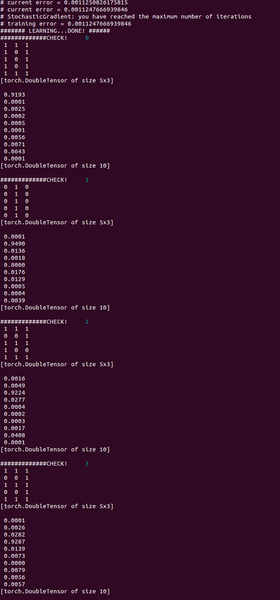
それぞれのデータ(行列データ)を認識すると、それに応じて、0〜9の位置の数値が1に近い数値が返ってきます。
※今回のプログラムでは、答えになる部分を数字にしたため、9などの数字としてますが、これを
0,0,0,0,0,0,0,0,1というデータ形式に変えるのも面白いと思います。
15個の数字の配置状況から、それに応じた答えを返す人工知能の完成です。
ここまでくると、なんか面白い(不気味?)ですよね。
IF文が全く存在しないのに、期待する答えが出てきてしまいます。
プログラム主体ではなく、データ主体で動作が決まるので、これまでのプログラム作成になれている人には特に違和感を感じるかもしれません。
(ちなみに…このプログラムにも落とし穴があって、データが1つがズレると、正しい答えが得られなくなってしまいます。それを解決する方法はまた次回以降でお話しします)
さらには、これまではプログラムの中で学習用データを作成していましたが、外部のデータを読み込んで処理をします。
まずは、以下のテキストデータをNUMBERS.CSVとしてセーブします。
========================= CSV FILEここの下から
1,1,1,1,0,1,1,0,1,1,0,1,1,1,1,0
0,1,0,0,1,0,0,1,0,0,1,0,0,1,0,1
1,1,1,0,0,1,1,1,1,1,0,0,1,1,1,2
1,1,1,0,0,1,1,1,1,0,0,1,1,1,1,3
1,0,1,1,0,1,1,1,1,0,0,1,0,0,1,4
1,1,1,1,0,0,1,1,1,0,0,1,1,1,1,5
1,1,1,1,0,0,1,1,1,1,0,1,1,1,1,6
1,1,1,0,0,1,0,0,1,0,0,1,0,0,1,7
1,1,1,1,0,1,1,1,1,1,0,1,1,1,1,8
1,1,1,1,0,1,1,1,1,0,0,1,0,0,1,9
========================= CSV FILEここの上まで
実はこのデータ、縦5、横3のピクセルで数字の0〜9を表しています。
例えば数字の9ならば以下のような形です。
===9===
1 1 1
1 0 1
1 1 1
0 0 1
0 0 1
=======
(数字の1が9の形に並んでいます)
これを横一列に並べれば、数字の9は…
1,1,1,1,0,1,1,1,1,0,0,1,0,0,1
というデータになります。
さらに、データを入れたCSVファイルの各行のいちばん右側の数字は、データに対する答えです。
こんな形で0〜9に対応するデータを用意し、それをニューラル・ネットワークで認識できるようにします。
※なお、torch7でCSVファイルを扱えるように、csvigoライブラリーをインストールしておく必要があります。
「luarocks install csvigo」でインストールしてください。
CSVファイルから読み込んだデータは、そのままでは行列データのtorch.Tensorではなく、連想配列といわれるテーブル形式なので、「1」という数字も実際にはテキストの「1」扱いになっているので、それを数値に変えてあげる作業が必要です。
で、パターン認識のプログラムは以下のようになります。
=====================================ここから
require 'nn'
require 'csvigo'
-- ####”luarocks install csvigo” でインストールしておいてください
-- CSVファイルのデータをロード
m=csvigo.load{path='NUMBERS.CSV',mode='large'}
print ("####### DATA LOAD! ######")
dataset={}
function dataset:size() return 10 end
-- 読み込んだデータをtorch.Tensorに直して学習出来るようにする。
for i=1,dataset:size() do
input =torch.Tensor(15)
output=torch.Tensor(10):zero()
input[1]=m[i][1]
input[2]=m[i][2]
input[3]=m[i][3]
input[4]=m[i][4]
input[5]=m[i][5]
input[6]=m[i][6]
input[7]=m[i][7]
input[8]=m[i][8]
input[9]=m[i][9]
input[10]=m[i][10]
input[11]=m[i][11]
input[12]=m[i][12]
input[13]=m[i][13]
input[14]=m[i][14]
input[15]=m[i][15]
a=m[i][16]
-- 10チャンネルの出力のうち、答えになるところを1に設定する
-- Torchの配列などは0スタートではなく、1がスタートになるので注意!
output[a+1]=1
dataset[i]={input,output}
print("###########",m[i][16])
print(input[1],input[2],input[3])
print(input[4],input[5],input[6])
print(input[7],input[8],input[9])
print(input[10],input[11],input[12])
print(input[13],input[14],input[15])
end
print ("####### DATASET! ######")
model=nn.Sequential();
model:add(nn.Linear(15,15))
model:add(nn.Tanh())
model:add(nn.Linear(15,30))
model:add(nn.Tanh())
model:add(nn.Linear(30,10))
-- 今回はソフトマックスも入れてみますが、これがなくともそれぞれの合計が1にならないだけで、順序そのものが入れ替わるなどの変化はありません
model:add(nn.SoftMax())
print ("####### MODEL SET OK! ######")
criterion = nn.MSECriterion()
trainer=nn.StochasticGradient(model,criterion)
trainer.learningRate=0.01
trainer.maxIteration=10000
print ("####### TARINER SET! ######")
trainer:train(dataset)
print ("####### LEARNING...DONE! ######")
-- 学習結果の検証
for i=1,dataset:size() do
input =torch.Tensor(15)
input[1]=m[i][1]
input[2]=m[i][2]
input[3]=m[i][3]
input[4]=m[i][4]
input[5]=m[i][5]
input[6]=m[i][6]
input[7]=m[i][7]
input[8]=m[i][8]
input[9]=m[i][9]
input[10]=m[i][10]
input[11]=m[i][11]
input[12]=m[i][12]
input[13]=m[i][13]
input[14]=m[i][14]
input[15]=m[i][15]
a=model:forward(input)
print ("#############CHECK!",i-1)
print (input:reshape(input,5,3),a)
end
=====================================ここまで
これをファイルに保存し、dofile 'ファイル名'で実行をすると…
それぞれのデータ(行列データ)を認識すると、それに応じて、0〜9の位置の数値が1に近い数値が返ってきます。
※今回のプログラムでは、答えになる部分を数字にしたため、9などの数字としてますが、これを
0,0,0,0,0,0,0,0,1というデータ形式に変えるのも面白いと思います。
15個の数字の配置状況から、それに応じた答えを返す人工知能の完成です。
ここまでくると、なんか面白い(不気味?)ですよね。
IF文が全く存在しないのに、期待する答えが出てきてしまいます。
プログラム主体ではなく、データ主体で動作が決まるので、これまでのプログラム作成になれている人には特に違和感を感じるかもしれません。
(ちなみに…このプログラムにも落とし穴があって、データが1つがズレると、正しい答えが得られなくなってしまいます。それを解決する方法はまた次回以降でお話しします)



