torch7で小さくディープラーニング(5)活性化関数の注意 [人工知能(ディープラーニング)]
今回は、「活性化関数」についての話です。
説明で使うのは、与えられた5つの数の中から、-1がどこにあるのかを見つける人工知能です。
前回は、入力5、出力5でしたが、今回は入力5、出力1です。
ちなみに、前回のプログラムを変更して学習させてみます。
=================================TYPE NG
require 'nn'
dataset={}
function dataset:size() return 100 end
for i=1,dataset:size() do
input=torch.Tensor(5)
for j=1,5 do
input[j]=torch.random(1,10)
end
x=torch.random(1,5)
input[x]=-1
output=torch.Tensor(1):zero()
output[1]=x
dataset[i]={input,output}
end
-- 人工知能モデルの設定
model=nn.Sequential();
model:add(nn.Linear(5,10))
model:add(nn.Tanh())
model:add(nn.Linear(10,1))
model:add(nn.Tanh())
criterion = nn.MSECriterion()
trainer=nn.StochasticGradient(model,criterion)
trainer.learningRate=0.01
trainer.maxIteration=1000
trainer:train(dataset)
-- torch.save('TEST.t7',model) 今回は使いませんのでコメントアウトします
-- ===================TEST
a=torch.Tensor(5)
for i=1,10 do
for j=1,5 do
a[j]=torch.random(1,10)
end
x=torch.random(1,5)
a[x]=-1
b=model:forward(a)
print("INPUT :"..a[1]..","..a[2]..","..a[3]..","..a[4]..","..a[5])
print("ANSWER:"..b[1])
print("------")
end
=================================
結果は、全く学習が進まずに、テスト結果もボロボロです。
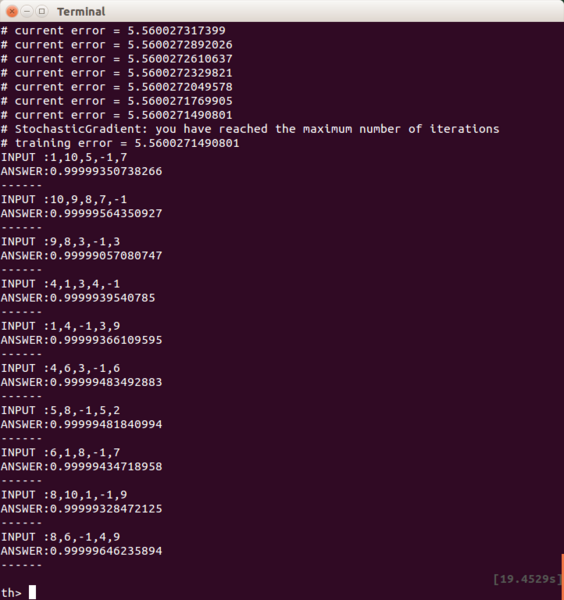
何が問題かというと、人工知能モデルの最後(出力の直前)にある活性化関数「Tanh」にあります。
活性化関数というのは、ぶっちゃけて言うと「入力値によってオン・オフされるスイッチ」です。
ただ、プログラムを作る人が任意でオン・オフするようなものではなく、「人工知能モデルが自分自身でオン・オフするためのもの」です。なので、これをいろいろなタイプのものに変更しても、なかなかプログラムを作った本人にはその変化の反応がダイレクトに伝わってこないもどかしさを感じたりもします。
で、このTanhですが、以下のような出力を返します。
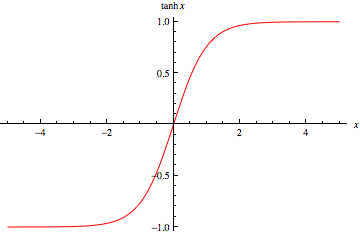
なんと、出力値が-1〜1です.
1以上の数値を与えても、1にしかなりません。
出力の直前にこれを入れてしまったために、答えが正しくならないのです。
では、もしこれを取り除いてしまったらどうなるでしょう…
=================================TYPE OK
require 'nn'
dataset={}
function dataset:size() return 100 end
for i=1,dataset:size() do
input=torch.Tensor(5)
for j=1,5 do
input[j]=torch.random(1,10)
end
x=torch.random(1,5)
input[x]=-1
output=torch.Tensor(1):zero()
output[1]=x
dataset[i]={input,output}
end
model=nn.Sequential();
model:add(nn.Linear(5,10))
model:add(nn.Tanh())
model:add(nn.Linear(10,1))
-- model:add(nn.Tanh()) コメントアウトします。
criterion = nn.MSECriterion()
trainer=nn.StochasticGradient(model,criterion)
trainer.learningRate=0.01
trainer.maxIteration=1000
trainer:train(dataset)
-- torch.save('TEST.t7',model)
-- ===================TEST
a=torch.Tensor(5)
for i=1,10 do
for j=1,5 do
a[j]=torch.random(1,10)
end
x=torch.random(1,5)
a[x]=-1
b=model:forward(a)
print("INPUT :"..a[1]..","..a[2]..","..a[3]..","..a[4]..","..a[5])
print("ANSWER:"..b[1])
print("------")
end
=================================
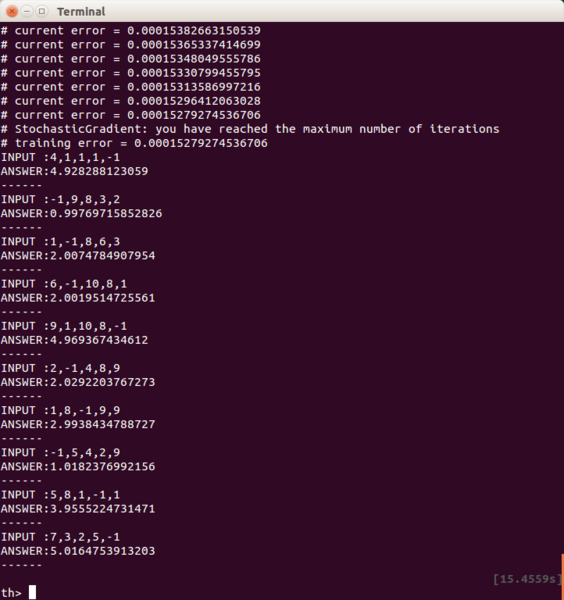
これだときちんと、その場所の数値(-1が左から1個目なら1,2個目なら2…)に近い値が返ってきます。
「いくら正しい答えが返ってきても、なんか活性化関数がないのはイヤだな」と考える人がいるかもしれません。
実は、ここには「活性化関数がない」のではなく、「恒等関数(入力値をそのまま出力する)がある」とも考えられる事も出来ます。(なんか、とんち話でごまかされた気がするかもしれませんが…)
また、ここに入力値がプラスの時には、数値をそのまま出力する「ReLU」を使っても問題ありません。
人工知能モデルをこんな感じで変更します。
====================
model=nn.Sequential();
model:add(nn.Linear(5,10))
model:add(nn.Tanh())
model:add(nn.Linear(10,1))
-- model:add(nn.Tanh())
model:add(nn.ReLU())
====================
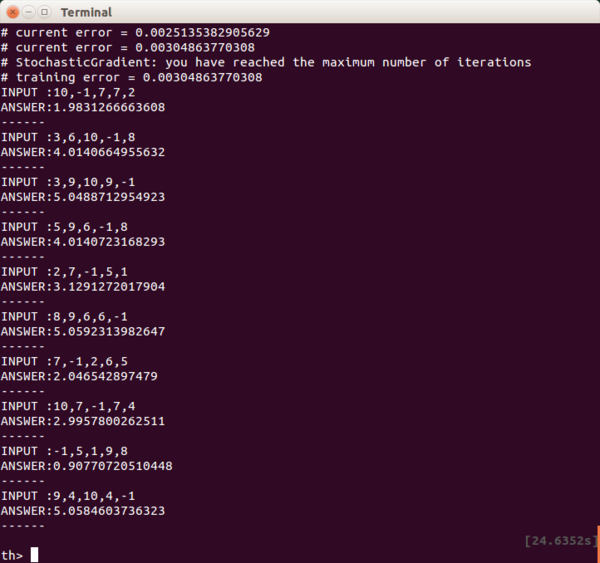
これでも問題なくこちらの意図するように動いてくれます。
※ただし、もし0以下のマイナスの出力値が欲しい場合に、出力の直前でReLUを組み込んだりすると、0にされてしまうので注意が必要です。
実は、以前は良くWEBで見られるサンプルには「Sigmoid(出力値は0〜1)」が使われていたり、WEBでは「TanhよりもSigmoidが性能が良い」という説明されていたので、意味もわからずに組み込んで、学習が進まなかったり、期待する出力が得られずにがっくりしていたのです。
活性化関数には、実は今回のような落とし穴があったりします。
まずは性能よりも、「出力値がどうなるか」が重要です。
説明で使うのは、与えられた5つの数の中から、-1がどこにあるのかを見つける人工知能です。
前回は、入力5、出力5でしたが、今回は入力5、出力1です。
ちなみに、前回のプログラムを変更して学習させてみます。
=================================TYPE NG
require 'nn'
dataset={}
function dataset:size() return 100 end
for i=1,dataset:size() do
input=torch.Tensor(5)
for j=1,5 do
input[j]=torch.random(1,10)
end
x=torch.random(1,5)
input[x]=-1
output=torch.Tensor(1):zero()
output[1]=x
dataset[i]={input,output}
end
-- 人工知能モデルの設定
model=nn.Sequential();
model:add(nn.Linear(5,10))
model:add(nn.Tanh())
model:add(nn.Linear(10,1))
model:add(nn.Tanh())
criterion = nn.MSECriterion()
trainer=nn.StochasticGradient(model,criterion)
trainer.learningRate=0.01
trainer.maxIteration=1000
trainer:train(dataset)
-- torch.save('TEST.t7',model) 今回は使いませんのでコメントアウトします
-- ===================TEST
a=torch.Tensor(5)
for i=1,10 do
for j=1,5 do
a[j]=torch.random(1,10)
end
x=torch.random(1,5)
a[x]=-1
b=model:forward(a)
print("INPUT :"..a[1]..","..a[2]..","..a[3]..","..a[4]..","..a[5])
print("ANSWER:"..b[1])
print("------")
end
=================================
結果は、全く学習が進まずに、テスト結果もボロボロです。
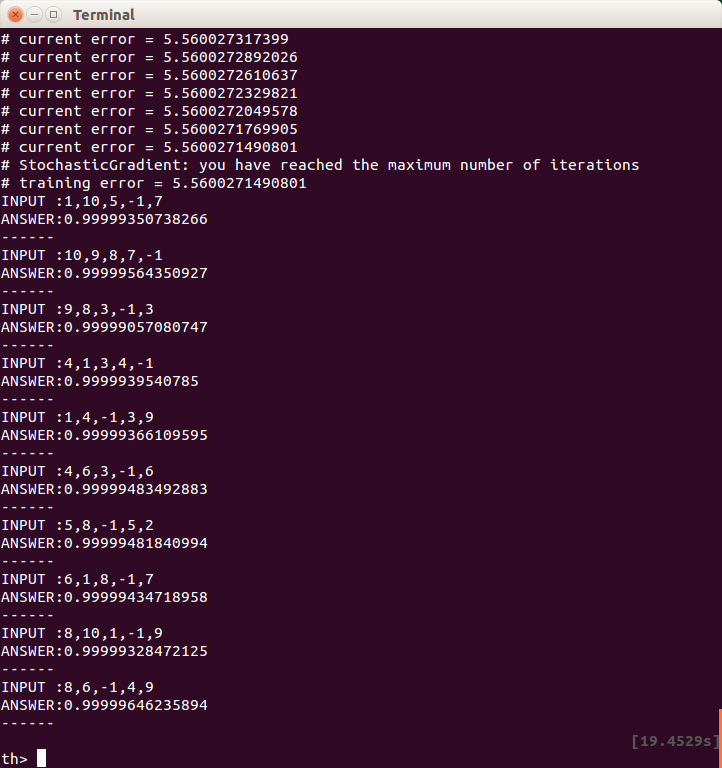
何が問題かというと、人工知能モデルの最後(出力の直前)にある活性化関数「Tanh」にあります。
活性化関数というのは、ぶっちゃけて言うと「入力値によってオン・オフされるスイッチ」です。
ただ、プログラムを作る人が任意でオン・オフするようなものではなく、「人工知能モデルが自分自身でオン・オフするためのもの」です。なので、これをいろいろなタイプのものに変更しても、なかなかプログラムを作った本人にはその変化の反応がダイレクトに伝わってこないもどかしさを感じたりもします。
で、このTanhですが、以下のような出力を返します。
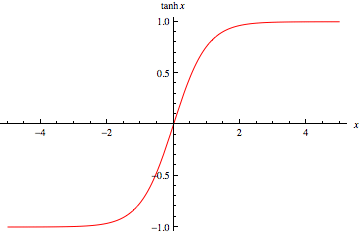
なんと、出力値が-1〜1です.
1以上の数値を与えても、1にしかなりません。
出力の直前にこれを入れてしまったために、答えが正しくならないのです。
では、もしこれを取り除いてしまったらどうなるでしょう…
=================================TYPE OK
require 'nn'
dataset={}
function dataset:size() return 100 end
for i=1,dataset:size() do
input=torch.Tensor(5)
for j=1,5 do
input[j]=torch.random(1,10)
end
x=torch.random(1,5)
input[x]=-1
output=torch.Tensor(1):zero()
output[1]=x
dataset[i]={input,output}
end
model=nn.Sequential();
model:add(nn.Linear(5,10))
model:add(nn.Tanh())
model:add(nn.Linear(10,1))
-- model:add(nn.Tanh()) コメントアウトします。
criterion = nn.MSECriterion()
trainer=nn.StochasticGradient(model,criterion)
trainer.learningRate=0.01
trainer.maxIteration=1000
trainer:train(dataset)
-- torch.save('TEST.t7',model)
-- ===================TEST
a=torch.Tensor(5)
for i=1,10 do
for j=1,5 do
a[j]=torch.random(1,10)
end
x=torch.random(1,5)
a[x]=-1
b=model:forward(a)
print("INPUT :"..a[1]..","..a[2]..","..a[3]..","..a[4]..","..a[5])
print("ANSWER:"..b[1])
print("------")
end
=================================
これだときちんと、その場所の数値(-1が左から1個目なら1,2個目なら2…)に近い値が返ってきます。
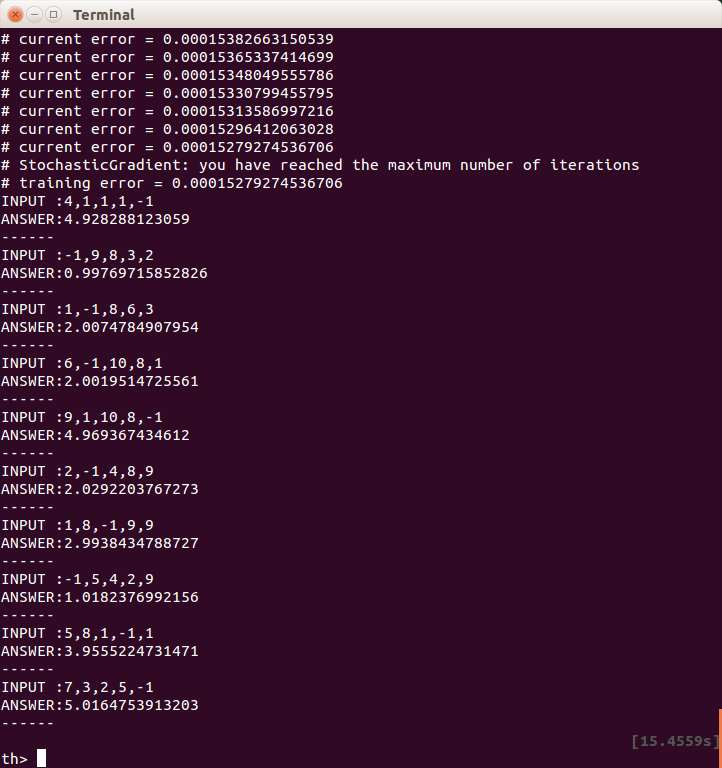
「いくら正しい答えが返ってきても、なんか活性化関数がないのはイヤだな」と考える人がいるかもしれません。
実は、ここには「活性化関数がない」のではなく、「恒等関数(入力値をそのまま出力する)がある」とも考えられる事も出来ます。(なんか、とんち話でごまかされた気がするかもしれませんが…)
また、ここに入力値がプラスの時には、数値をそのまま出力する「ReLU」を使っても問題ありません。
人工知能モデルをこんな感じで変更します。
====================
model=nn.Sequential();
model:add(nn.Linear(5,10))
model:add(nn.Tanh())
model:add(nn.Linear(10,1))
-- model:add(nn.Tanh())
model:add(nn.ReLU())
====================
これでも問題なくこちらの意図するように動いてくれます。
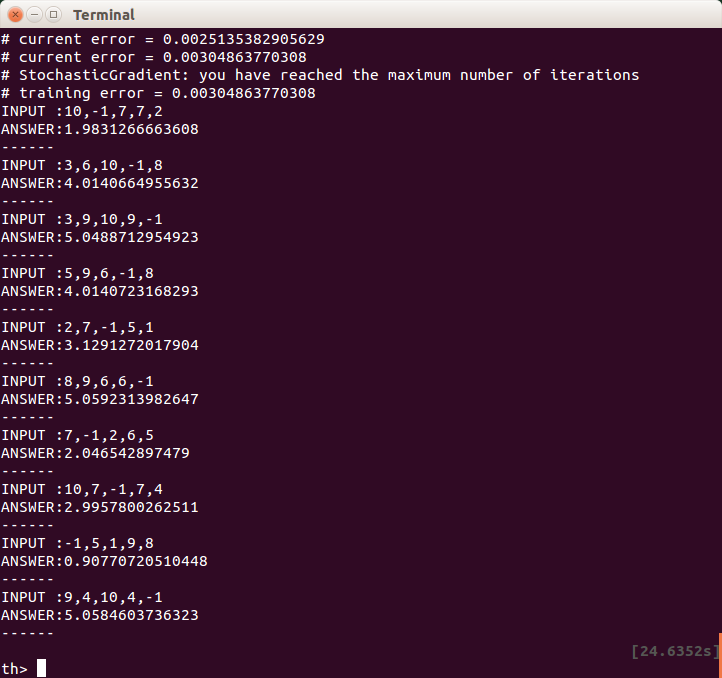
※ただし、もし0以下のマイナスの出力値が欲しい場合に、出力の直前でReLUを組み込んだりすると、0にされてしまうので注意が必要です。
実は、以前は良くWEBで見られるサンプルには「Sigmoid(出力値は0〜1)」が使われていたり、WEBでは「TanhよりもSigmoidが性能が良い」という説明されていたので、意味もわからずに組み込んで、学習が進まなかったり、期待する出力が得られずにがっくりしていたのです。
活性化関数には、実は今回のような落とし穴があったりします。
まずは性能よりも、「出力値がどうなるか」が重要です。




コメント 0